Пример, на котором покажу, как с помощью модуля Parser, можно за 45 секунд спарсить контент сайта DrupalSN :)

Открываем admin/structure/parser_jobs и жмём ссылку Add job parsing.
Заполняем основные поля:
Название задания — Парсинг постов с drupalsn.ru
Стартовый URL — http://drupalsn.ru/
Парсить только с этого же домена — Да
В поле URL тестовой страницы указываем пример типичной страницы с контентом — http://drupalsn.ru/blogs/modules/350.
В поле Глубина указываем 2, это максимальная глубина ссылок по которым нужно пройтись вглубь, чтобы спарсить все посты сайта. Т.е. логика такая — модуль скачает страницу указанную в поле Стартовый URL, найдёт на ней ссылки и скачает страницы по этим ссылкам (это будут страницы с глубиной 1), дальше для каждой страницы алгоритм повторится (это будут страницы с глубиной 2) и на этом работа парсера закончится. Таким образом мы скачаем главную, посты расположенные на главной, страницы на которые ссылается пагинатор и посты на этих страницах. Кто хоть раз пользовался Teleport Pro, должен помнить такую опцию при создании проекта.
Если парсер запускается в первый раз, то можно ограничить количество создаваемых нод в поле Ограничить число нод например пятью. Это позволит не ждать копирование всего сайта, так как процесс прервётся после создания пятой ноды.
В белом списке адресов указываем маску адресов, по которым располагаются посты — http://drupalsn.ru/blogs/*/* и страницы, имеющие ссылки на посты — http://drupalsn.ru/blogs?page=*.
Чёрный список оставляем пустым. Он нужен, когда необходимо закрыть адреса, которые подпадают под белый список, например в нём могло быть что нибудь типа http://drupalsn.ru/blogs/*/*/comments.
В поле Код проверки для дальнейшего парсинга страницы нужно написать код, который однозначно скажет — эту страницу нужно распарсить в ноду. Т.е. нужно по каким то признакам в html коде, опознать страницу с постом. На DrupalSN таким признаком является класс node-type-blog у тега body:

Код с использованием библиотеки phpQuery будет:
return $doc->find('body.node-type-blog')->length() == 1;Или на чистом php:
return strpos($page, 'node-type-blog') !== false;Проверяем код с помощью кнопки "проверить" над полем ввода:

Если выводится 1, то двигаемся дальше.
Выбираем тип материала — Article и язык und.
В филдсете Поля, в поле title, пишем код, который вернёт заголовок поста. Заголовки на DrupalSN заключены в тег h2 с классом page_title:
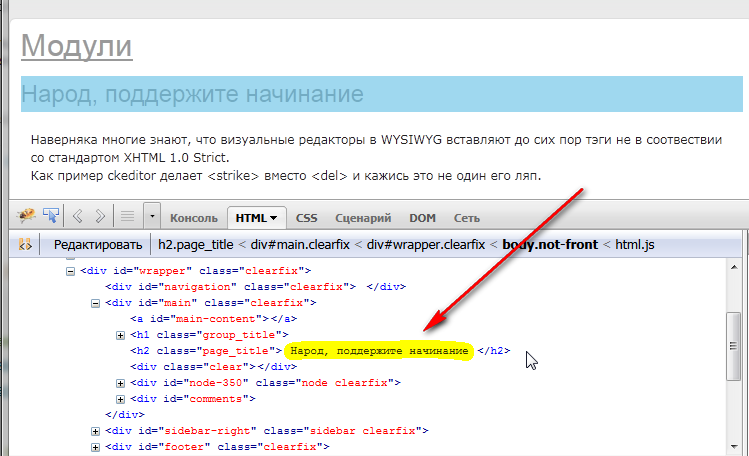
Значит код будет:
return $doc->find('h2.page_title')->text();Без phpQuery пришлось бы поработать с помощью preg_match, как-нибудь так:
if (preg_match('#<h2 class="page_title">(.+)</h2>#', $page, $matches)) {
return $matches[1];
}Жмём кнопку проверить и двигаемся дальше:

Сам текст поста обёрнут в два div-a с классами node_content и _blank:
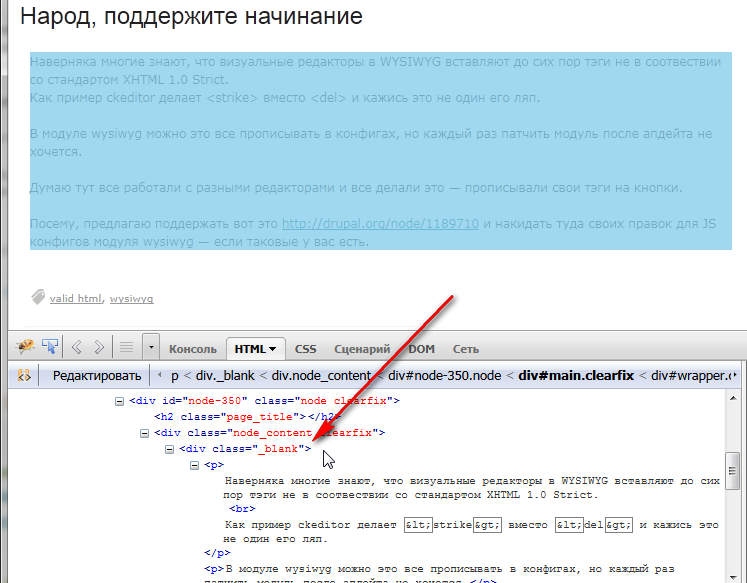
Следовательно код для поля body будет:
return $doc->find('.node_content ._blank')->html();Проверяем:
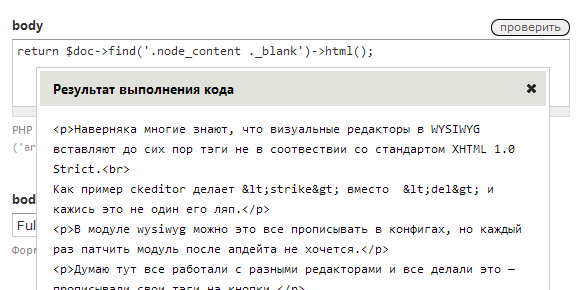
Теги обёрнуты в div с классом node_tage:
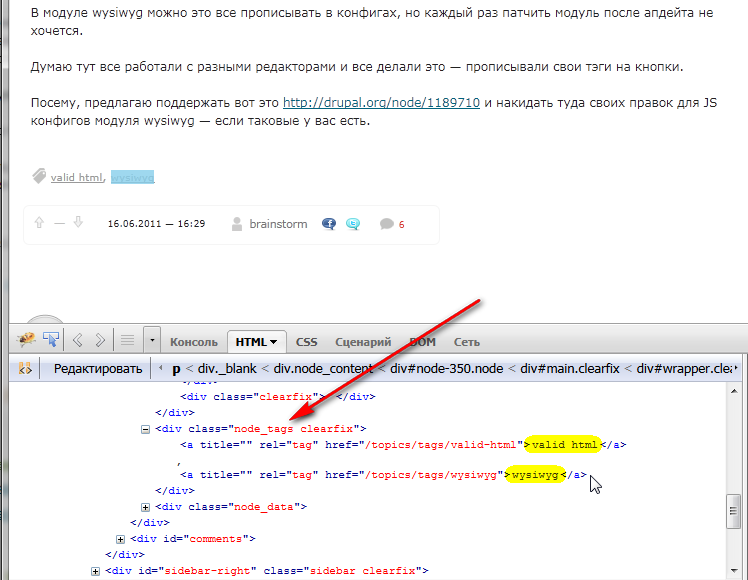
Так как тегов может быть больше одного, то в поле field_tags нужно возвращать массив:
$terms = array();
foreach ($doc->find('.node_tags a') as $a) {
$terms[] = pq($a)->text();
}
return $terms;Проверяем:
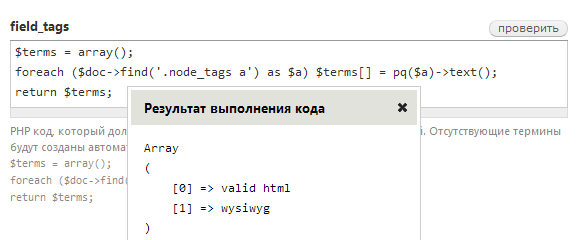
Вот и всё. Жмём Сохранить задание и Начать парсинг и наслаждаемся результатом:
P.S: ни в коем случае не поощряю воровство авторского контента.
Комментарии
А если код такой изменится что нибудь?
Добавляю Product через Entity Wrapper для Display. Все отлично. Но как сохранить фотографии к Product и передать результат в Entity Wrapper?
Warning: Invalid argument supplied for foreach() в функции _parser_set_property() (строка 1590 в файле D:\server\OpenServer\domains\pencil.ru\sites\all\modules\parser-master\parser.inc).
подскажите пожалуйста, что это за ошибка? как бороться?
а примерно понял почему ошибка, формат поля который парсер пытается засунуть в ноду не совпадает с форматом сущности на сайте
а примерно понял почему ошибка, формат поля который парсер пытается засунуть в ноду не совпадает с форматом поля сущности на сайте
Здравствуйте! Спасибо за модуль, текст парсится отлично.
Однако, возникает проблема с изображениями, выдает следующую ошибку:
Однако из задания в примере изображения загружаются верно. Я только начинаю осваивать drupal, поэтому возможно ошибку какую-то глупую допустил?
В настройках задания в поле "Image" прописано следующее:
В типе содержимого поле image соответственно также имеется. Заранее спасибо за ответ!
Проблему решил, обсуждалась в другой ветке комментариев.
В настройках типа содержимого в параметрах поля "Image" было указано неограниченное количество изображений. А код был написан под одно изображение, поэтому выдавалась ошибка "There can be only numerical keyed items in a list.", которую я сначала в логах не заметил почему-то. Установил ограничение на 1 изображение - и все заработало!
Хочу сохранить теги постов в словарь tags, причем создать их при парсинге. Код из примера с drupal.org сайтом теги не создает, а parser_create_terms_hierarchy($terms, $vocabulary) создает термины, последовательно вложенные друг в друга. Подскажите, что нужно сделать чтобы теги создавались?
Спасибо за модуль!
Спасибо за ответ, я всё пишу правильно:
Проблема в том, что я удаляю из $doc див с тегами в предыдущем филдсете "The main body text (body)", и при обращении к $doc в филдсете "Теги (field_tags)" он уже их не содержит и $t пустая. Причем, даже если я работаю со своей переменной (как ниже) - $doca, всё равно тегов нет.
Вот мой код в The main body text (body):
http://php.net/manual/ru/language.oop5.cloning.php
Спасибо, xandeadx, но если я заменю $doca = $doc; на $doca = clone $doc;, то ничего не изменится(((
У меня есть идея теги создавать перед body (поменять местами в модуле эти вещи).
Есть ли еще варианты?
clone должно работать, других вариантов не знаю
Посмотрела код модуля: не так-то просто поменять местами в форме body и термины.
Может быть есть способ иначе не выводить в body определенный див с классом? Приходит на ум либо для тегов парсить html код страницы в $page, либо в body не удалять див с классом, а скрывать его display:none;
Похоже, я справилась!
Нужно сохранить див перед удалением $qwerty = $doca->find('.single-entry .post-entry-bottom'); в body и потом в тегах обращаться к $qwerty:
Еще один вопрос - в каком формате передавать дату создания? Timestamp или другое?
timestamp
Добрый день! Подскажите пожалуйста как спарсить строку вида
<img class="img-full-width" src="/media/articles_photos/700x400_q84_crop.jpg" alt="...">Осталось только изображение получить, остальное все работает)
Люди добрые помогите с полем цены в ubercart.. ни в какую не хочет парситься...
"Warning: Invalid argument supplied for foreach() в функции _parser_set_property"
Добрых людей не осталось((
Делаю всё как Вы написали. При проверке данные корректно отображаются, но сущности не создаются. При исполнение парсер обрабатывает только URL'ы.
Сущности создано: 0;
Не удалось создать/сохранить сущностей: 0
Что нужно сделать, чтобы создавались сущности? В постобаботку, что-то добавить или что? Подскажите пожалуйста!
Хотел запарсить бесплатные css кнопки с открытых источников и без текстового содержимого в body.
Тут или телепатия, или дебажить. Слишком неочевидно, что у вас там происходит.
Как исправить ошибку: Файл " http://site.com/uploads/1273.jpg " закачан не будет, так как его тип "jpg " не в списке допустимых? Вручную всё нормально добавляется. Сам формат разрешен в настройках полей и в IMCE. PNG парсит нормально, а JPG не хочет. В блеклисте ничего нет.
Парсю изображения таким кодом:
Здравствуйте, спасибо за шикарный модуль, есть вопрос как парсить поля типа entity_reference
Доброе утро! А под друпал 8 есть интеграция?
Вот модуль для Drupal 8 - https://www.drupal.org/project/content_parser
Он начинает работать после правки одного файла ядра
https://www.drupal.org/project/content_parser/issues/3117403
Жаль, пока в D8 неудалось настроить работу с изображениями , текст парсит отлично а вот , изображения отказываеться принимать.
Добавить комментарий