Пример, на котором покажу, как с помощью модуля Parser, можно за 45 секунд спарсить контент сайта DrupalSN :)

Открываем admin/structure/parser_jobs и жмём ссылку Add job parsing.
Заполняем основные поля:
Название задания — Парсинг постов с drupalsn.ru
Стартовый URL — http://drupalsn.ru/
Парсить только с этого же домена — Да
В поле URL тестовой страницы указываем пример типичной страницы с контентом — http://drupalsn.ru/blogs/modules/350.
В поле Глубина указываем 2, это максимальная глубина ссылок по которым нужно пройтись вглубь, чтобы спарсить все посты сайта. Т.е. логика такая — модуль скачает страницу указанную в поле Стартовый URL, найдёт на ней ссылки и скачает страницы по этим ссылкам (это будут страницы с глубиной 1), дальше для каждой страницы алгоритм повторится (это будут страницы с глубиной 2) и на этом работа парсера закончится. Таким образом мы скачаем главную, посты расположенные на главной, страницы на которые ссылается пагинатор и посты на этих страницах. Кто хоть раз пользовался Teleport Pro, должен помнить такую опцию при создании проекта.
Если парсер запускается в первый раз, то можно ограничить количество создаваемых нод в поле Ограничить число нод например пятью. Это позволит не ждать копирование всего сайта, так как процесс прервётся после создания пятой ноды.
В белом списке адресов указываем маску адресов, по которым располагаются посты — http://drupalsn.ru/blogs/*/* и страницы, имеющие ссылки на посты — http://drupalsn.ru/blogs?page=*.
Чёрный список оставляем пустым. Он нужен, когда необходимо закрыть адреса, которые подпадают под белый список, например в нём могло быть что нибудь типа http://drupalsn.ru/blogs/*/*/comments.
В поле Код проверки для дальнейшего парсинга страницы нужно написать код, который однозначно скажет — эту страницу нужно распарсить в ноду. Т.е. нужно по каким то признакам в html коде, опознать страницу с постом. На DrupalSN таким признаком является класс node-type-blog у тега body:

Код с использованием библиотеки phpQuery будет:
return $doc->find('body.node-type-blog')->length() == 1;Или на чистом php:
return strpos($page, 'node-type-blog') !== false;Проверяем код с помощью кнопки "проверить" над полем ввода:

Если выводится 1, то двигаемся дальше.
Выбираем тип материала — Article и язык und.
В филдсете Поля, в поле title, пишем код, который вернёт заголовок поста. Заголовки на DrupalSN заключены в тег h2 с классом page_title:
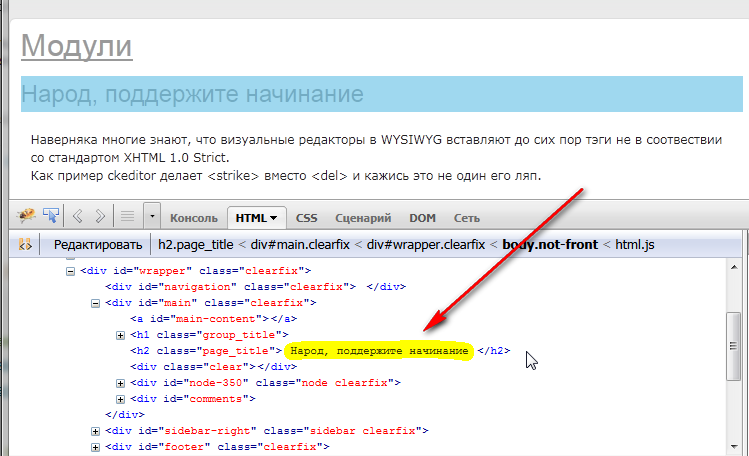
Значит код будет:
return $doc->find('h2.page_title')->text();Без phpQuery пришлось бы поработать с помощью preg_match, как-нибудь так:
if (preg_match('#<h2 class="page_title">(.+)</h2>#', $page, $matches)) {
return $matches[1];
}Жмём кнопку проверить и двигаемся дальше:

Сам текст поста обёрнут в два div-a с классами node_content и _blank:
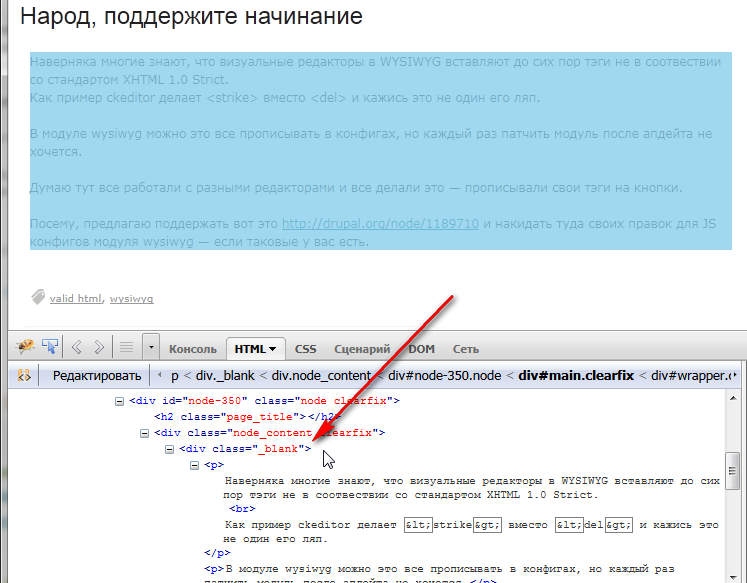
Следовательно код для поля body будет:
return $doc->find('.node_content ._blank')->html();Проверяем:
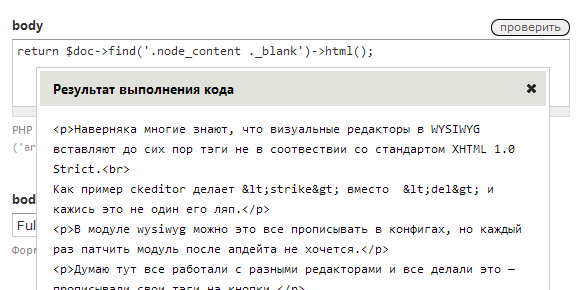
Теги обёрнуты в div с классом node_tage:
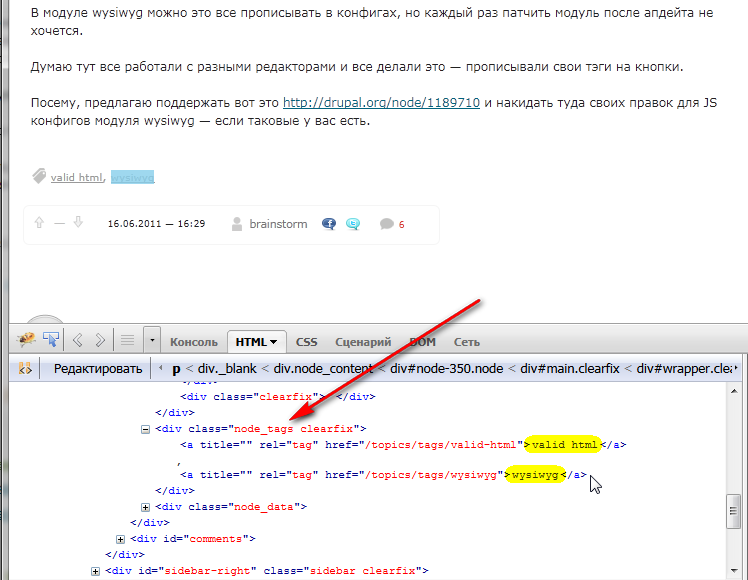
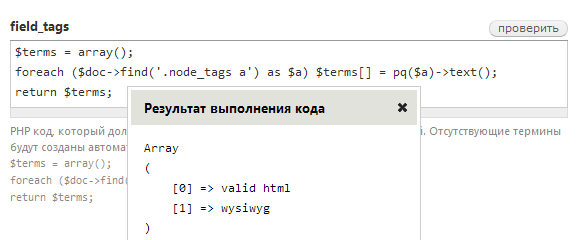
Так как тегов может быть больше одного, то в поле field_tags нужно возвращать массив:
$terms = array();
foreach ($doc->find('.node_tags a') as $a) {
$terms[] = pq($a)->text();
}
return $terms;Проверяем:
Вот и всё. Жмём Сохранить задание и Начать парсинг и наслаждаемся результатом:
P.S: ни в коем случае не поощряю воровство авторского контента.
Комментарии
Добрый день, такая же проблема как и в комментарии http://xandeadx.ru.s2.gvirabi.com/blog/drupal/399#comment-4838
В логах апача пишет, что не может найти файл
/var/www/imya_sayta/parserГде ещё можно поискать проблему ?
Включил "чистые" ссылки - заработало.
Поняла, наконец то где настраивается задержка между запросами :) — в более новой версии :)
Работает!
В Журнале такая запись появляется. Что с ней делать, не знаю...
Notice: Undefined index: display_default в функции entity_metadata_field_file_create_item() (строка 579 в файле /home/u8478/domains/site.ru/sites/all/modules/entity/modules/callbacks.inc).
https://drupal.org/node/1831660
Пропатчила, замечания в журнале пропали
Забыла про гугл. Могла сама поискать ответ.
Большое спасибо!
Как быть, если field collection представлен в виде мультиполя? Одно значение я понял как сохранить и привязать к ноде. Но если с одной страницы нужно парсить несколько field collection в одну ноду, что тогда делать?
так же
То есть, сначала нужно отпарсить ноды, потом запустить парсер на field_collection? Но так же занесет только одну field_collection в ноду, разве нет?
field_collection_item это сущность, создавайте сколько нужно
Сделал как говорил Андрей здесь http://xandeadx.ru/blog/drupal/554#comment-7383
У меня проблема с кодировкой. Пробовал по примеру с DrupalSN (там указана utf-8).
но при первой же проверке поля "title" вместо текста на русском языке вылезают кракозябры. Если их игнорировать и идти дальше, то в последствии вылезает ошибка. Пробовал различные варианты с iconv("windows-1251", "utf-8", $page) - ничего не помогает. Проверил все свои настройки Msql, PHP - везде настроено на utf-8. Пока не знаю, что дальше делать.
Здравствуйте, не получается создать массив значений типа: list
не могу создать сущность field_collection_item используя:
$field_collection_item = entity_create('field_collection_item', array('field_name' => 'field_etaps'));
$field_collection_item->setHostEntity('node', $node);
не пойму что куда относиться, объясните пожалуйста
Спасибо.
$field_collection_item->field_num_etap[LANGUAGE_NONE][0]['value'] = var1;
$field_collection_item->field_descr_etap[LANGUAGE_NONE][0]['value'] = var2;
$field_collection_item->field_photos[LANGUAGE_NONE][0]['fid'] = var3;
return $field_collection_item;
Saiman, вам нужно привазываться не к переменной $node(так как ее там нет), а к переменной $entity. И возвращять нужно не колекцию, а масив с указанием идентификатора колекции. По коду, который я вставил немного выше, у меня все получилось.
Скажите пожалуйста, как быть если на сайте источнике тег body вообще не обозначен CSS символом, а #content находится в глубине кода?
найдите другие признаки, по которым можно определить страницу с контентом
Все разобрался! Модуль просто бомба! Огромадное спасибо автору! Остался один вопрос. Какой код вставлять в поле изображения? Буду признателен если кто-то подскажет.
в комментариях к полю всё подробно расписано
Еще один вопрос. Как сформулировать массив, чтобы вернуть значение поля "Product", которое внутри так же содержит поля?
Я коментарии к полю понял так:"return $doc->find(array(return $doc->find('#cclr')->text(), return $doc->find('b.pr')->text(), return $doc->find('b.pr')->text(),
return $doc->find('h1')->text();))->text()))->list;", но получаю ошибку. Поправите меня пожалуйста.
https://www.google.ru/search?q=основы+php
Вот варианты кода к полю "Product":
'sku' = $doc->find('#cclr')->text();
'title' = $doc->find('h1')->text();
'commerce_price' = $doc->find('b.pr')->text();
return array(
'sku',
'title',
'commerce_price'
);
$sku = $doc->find('#cclr')->text();
$title = $doc->find('h1')->text();
$commerce_price = $doc->find('b.pr')->text();
return array(
$sku,
$title,
$commerce_price,
);
Что теперь у меня не так
Возник вопрос - как парсить в Field collection?
Например, field_collection состоит из term_reference_field и text_field.
Парсер видит именно filed_collection в ноде, а не поля по отдельности, что и логично, и предлагает
Так можно ли парсить в field_collection? Прошу, помогите с решением.
Выдает вроде как годный для моего field_collection список через запятую, не парсится все-равно в field_collection.
Я вижу у коментатора выше схожий вопрос про field_collection
в одном задании создавайте сущность field collection, в другом связывайте её с нодой
И еще раз большое спасибо!
Вот только что за "PHP код для поля Host entity " - что подразумевается под Host entity и что должно возвращать поле? Это нода с которой связывать и соответвенно там должнен быть, например NodeID или я ошибаюсь?
entity wrapper родительской ноды
Как получить entity wrapper родительской ноды если ноды еще нет до парсинга?
Читатели были бы очень благодарны, если бы Вы сделали примеры с парсингом field_collection.
Пример:
Есть 2 коллекции полей field_inputs и field_outputs.
Создаю 2 задания. Рассмотрим 1 из них:
Тип сущности - field collection item
Подтип сущности - field_inputs
Remote id - ?
Host entity (host_entity) * - ?
Taxonomy term field - понятно
Decimal field - тоже понятно
Сохранить и Начать
field_outputs сделать по аналогии.
Потом как я понял надо создавать парсинг нужной ноды и в поля
field_inputs и field_outputs вызывать то, что получилось в предыдущих двух заданиях - но каким кодом это вызвать?
И еще один вопрос про последовательность и синхронизацию всего этого. Допустим мне надо спарсить ноду с полями + с двумя collection field. У меня есть 3 задания (если я описал свое понимание верно выше) - два для парсинга field_collection и одно для парсинга ноды - как все это синхронизируется? В результате нужно будет вызвать только задание парсинга ноды, а collection field задания подтянутся сами и нода корректно сформируется?
создайте сначала ноды, потом коллекции. проявите фантазию
прошу, ответье на 3 вопроса
Remote id - ?
Host entity (host_entity) * - ?
каким кодом вызывать сформированные collecion field в ноду?
Фантазия другим занята:) да и сначал создавать ноды потом коллекции ресурсоемко будет при >100 000 нод по 2 коллекции в каждой
Ребята привет. Парсер рабочий! Текст переносится на ура! Всё круто. Но не могу настроить парс картинок, там неполные ссылки типа /images/blablabla.jpg то есть корневой ссылки нет. Пожалуйста, объясните недалекому, как их спарсить.
что такое "корневая ссылка"?
Замечательная функция в модуле задавать маску страниц для обхода,
однако очень не хватает указания на ссылку "следующая страница" при помощи phpQuery, чтобы парсер последовательно шел вперед и брал только 1 ссылку для следующей страницы.
Неужели никак не реализовать функцию в парсере - "Не обходить уже пройденные/обработаенные страницы"?
Спасибо. Очень помогла статья для знакомства с темой парсинга.
Проясните, пожалуйста, назначение белого и черного списка. Удобно использовать один из них: белый - если необходимо парсить ограниченное число типов страниц, тогда задается только белый список, остальное все пропускается, и черный - если наоборот необходимо парсить почти все, за исключением отдельных типов страниц. Если в белом списке заданы два шаблона урл, которые необходимо парсить, зачем задавать черный список (ведь ссылок на странице может быть огромное количество). Или есть какой-то нюанс?
Спасибо!
Сорри, невнимательно разобралась в примере. Вопрос снимается.
Всем день добрый.
А можно сделать следующее?
При создании ноды парсить только одну страницу указывая url
Т.е. при добавлении содержимого/ноды, вставлять в поле ссылку и парсить только контент страницы с этим адресом?
нельзя
А может подскажете готовое решение, для такой задачи.
Хочется парсить контент только по определенному url и вводить его при создании ноды.
готовых решений нет
Произошло следующее не совсем понятное поведение. Был добавлен и оттестирован новый job parsing. На следующий день он самопроизвольно запустился на сайте и продолжал работу когда этот job parser был удален и даже когда был отключен модуль Parser! При этом он полностью игнорировал установленные изначально настройки по задержке между запросами и периодичностью запуска в фоновом режиме. Как его остановить? :) Там 65000 сущностей, он пока скачал только 13000. Все облазил, никаких заданий по расписанию и пр. нет, где это отключать - непонятно, остается снести сайт, но не хочется. Реально, процесс вышел из-под контроля. )) Когда корректируешь это задание таким образом, чтобы он скачал скажем 5 страниц, оно послушно это делает и завершается, но тот процесс продолжается. P.S. было бы весело, но мне засуспендили акк на хосте изза перегрузки процессора, после переговоров включили вновь и скрипт успешно продолжил свою работу, что и делает до сих пор. ))) P.P.S. Пытался удалять вновь создаваемый кэш в папке parser_cache - бестолку. Как его остановить??? ))) Куда оно прописывается?
беги форест беги
Ну я выяснил, что это запущен Branch. А как его теперь остановить?
Сорри, Batch ))
убить php процесс
Хорошо, но он какого-то самостоятельно запускается. Причем, в разное время. Где это посмотреть можно?
Возможно таким способом скопировать темы форумов и комментарии к ним с сайта ucoz на сайт друпал7
Доброй ночи!
С вечера сижу, пытаюсь спарсить в field collection. Уже раза четыре базу запарывал :(
Делаю так:
В итоге получаю ошибку:
Ошибка при записи в $entity_wrapper->field_diagnostics: Invalid data value given. Be sure it matches the required data type and format.
Value:
Array
(
[0] => Array
(
[value] => 1414
)
)
Но что самое интересное, правильная запись field collection создается и видна при редактировании материала, а выводится другая. Что видно в примере ниже: value и revision_id разные!!! При чем с каждым запуском скрипта, расхождение между ними увеличивается, и лечится это только перезаливкой базы :(
[field_diagnostics] => Array
(
[und] => Array
(
[0] => Array
(
[value] => 1414
[revision_id] => 1415
)
)
)
Далее, если последнюю строчку заменить на:
return $field_collection_item->item_id;То результата просто не будет, как и ошибок...
п.с. Замечательный модуль, автору спасибо! phpQuery тоже понравился, раньше не использовал :) Осталось только прикрутить эти коллекции полей..
парсите отдельным заданием сущности типа field collection item
Плиз, расскажите, как их потом соединить?
Если в одной ноде около 50 коллекций, а самих нод около 1000.
указать у field collection item родительскую сущность в host entity
Ок! Заход номер два! :)
Создал новый парсинг с типом сущности: "Элемент коллекции полей". В поле "Host entity" вывожу id ноды, к которой хочу присоединить коллекцию.
Делаю так:
На выходе ошибка:
Ошибка при записи в $entity_wrapper->host_entity: Invalid data value given. Be sure it matches the required data type and format.
Value:
171
И вторая:
Ошибка при сохранении сущности: Unable to create a field collection item without a given host entity..
Value:
FieldCollectionItemEntity Object
(
[fieldInfo:protected] =>
[hostEntity:protected] =>
[hostEntityId:protected] =>
[hostEntityRevisionId:protected] =>
[hostEntityType:protected] =>
[langcode:protected] => und
[item_id] =>
[revision_id] =>
[field_name] => field_repair_diagnostics
[default_revision] => 1
[archived] =>
[entityType:protected] => field_collection_item
[entityInfo:protected] => Array
.........
В связи с последней пробовал последнюю строку менять на:
Все равно не работает, ошибки те же..
И еще пару вопрос, созданные коллекции полей не прикрепленные к материалам, в базе все равно сохраняются?
Спасибо!
насколько помню надо возвращать или загруженный объект ноды, или загруженный entity_metadata_wrapper ноды. точно не помню
Плиз, не могли бы вы посмотреть как это правильно делается? Перепробовал уже кучу вариантов.. :(
Вопросы по данной теме были и раньше. Думаю пример от вас, будет многим полезен!
Итак, правильный ответ:
Здравствуйте хочу сказать вам спасибо за столь хороший парсер, но есть вопрос как можно допустим для новости спарсить ещё одну страницу с картинками.
Есть страница http://site.ru/novost.html
А её картинка (картинки) находятся на отдельной странице http://site.ru/kartinki/novost.html
Как бы сделать это помощью вашего парсера.
Здравствуйте хочу сказать вам спасибо за столь хороший парсер, но есть вопрос как можно допустим для новости спарсить ещё одну страницу с картинками.
Есть страница http://site.ru/novost.html
А её картинка (картинки) находятся на отдельной странице http://site.ru/kartinki/novost.html
Как бы сделать это помощью вашего парсера.
Понимаю что через parser_get_entity_id_by_remote_id нахожу remote id, но в душе не понимаю как обновить запись и добавить картинку
А несколько картинок закачать невозможно как я понимаю?
модуль поддерживает поля с любым количеством значений
А как можно загрузить допустим 2 картинки.
у меня сейчас что-то вроде этого.
array(
'file' => $file,
'alt' => $alt,
)
а как вернуть 2 массива, пробовал поместить их в массив не получилось.
возвращайте двумерный массив
Спасибо большое, как то я туплю....
Идеально парсит только не могу понять у парсера есть ограничение сколько линков брать со стартовой страницы?
нету
В общем спасибо что вы есть, создали такой прикольный модуль и что помогаете таким идиотам как я!
А можно как-то парсеру сказать что-бы, он не загружал стартовый URL?
что он тогда парсить должен?
Ну как бы просто что-бы он только брал адреса с неё, а не создавал запись просто это не страница с новостью, а он её пытается добавить её как новость и из-за этого пишет ошибку в журнал.
Кстати интересный момент, а если страница которую парсер уже спарсил обновилась допустим не весь текст в ней, а определённые значения которые парсер вытягивает, то сущность тоже обновится при выключенной галочке "Не обновлять сущности ".
В смысле про сущность это вопрос :) обновится ли она?
заполните поле "Код проверки для дальнейшего парсинга страницы"
Да опять моя глупость спасибо вам. А про сущность, парсер каждый раз проверяет не изменился ли там контент?
не проверяет
return array(array(
'file' => $file,
'alt' => $alt,
),
array(
'file' => $file,
'alt' => $alt,
));
Если сделать так с картинками, то не загружает вначале не заметил, он в проверке выводит всё ок, а загрузку почему то не делает.
читайте логи
Критических нету вообще теперь ;)
Есть замечание:
Notice: Undefined index: file в функции _parser_prepare_field_file() (строка 119 в файле /sites/all/modules/xandeadx-parser-0d12224/parser_prepare_field.inc).
что-то не так делаете
Посмотрел, он пишет что нету файла хотя кнопка проверить говорит:
Array ( [0] => Array ( [file] => http://site.ru/screenfiles/fixwin.png [alt] => Скриншот )
[1] => Array ( [file] => http://site.ru/screenfiles/fixwin.png [alt] => Скриншот ) )
Когда написал только заметил что файлы дублируются.
Не в этом дело к сожалению теперь 2ой массив выводит правильно линк, но не одна из картинок не загружается. Я вам наверное уже наскучил...
В общем перелазил весь сайт прочитал ещё раз все комментарии и всё в пустую вот у девушки была проблема очень похоже на мой вариант: http://xandeadx.ru/blog/drupal/554#comment-10389
не работает если засовывать в двумерный массив ну никак.
Ну парсер всё равно классный даже если можно только одну картинку пихать просто думал парсить все.
В общем целом опять моя тупость привела к этому. Если хотите загружать не 1ну фотографию укажите друпалу сколько можно загружать фотографий стандартно стоит 1..........
Подскажите, а можно ли как нибудь переименовывать закачанные файлы.
нет
В смысле закачиваемые парсером
?
нельзя
а как спарсить ссылку вида: http://kabinet-design.com/engine/download.php?id=57
тогда???
В смысле получить оттуда файл.
А модуль парсит страницы открытые в popup, подгруженные ajax'ом?
имеется каталог, финальная страница для парсинга имеет вид:
ссылка соответственно -
Ходит он по таким ссылкам? Парсит такие страницы?
нет
ок, спасибо.
A pod drupal 6 net parsera?
здравствуйте. вроде всё настроил, проверил, запустил и в итоге ни одна сущность не создалась. создавал commerce product
Парсинг завершён.
Обработано страниц: 320
Скачано URL: 22
URL взято из кэша: 1
Не удалось скачать URL: 0
Создано сущностей: 0
Обновлено сущностей: 0
Затрачено времени: 00:00:20
Новых сообщений в системном журнале: 0
в чём может быть проблема? если надо могу скинуть скрины настроек
прогнал, маленькую глубину поставил, всё заработало
Здравствуйте, подскажите как вернуть значение идущим за словом Артикул: в таком примере?
как получить YYYYYYYYY? всю голову сломал уже, заранее спасибо!
спасибо, но при проверке ничего не возвращает
Добавить комментарий